[반도체 스타트업 논문 리뷰 1] HyperAccel
Paper Title: "LPU: A Latency-Optimized and Highly Scalable Processor for Large Language Model Inference" [1]
최근 국내 AI 반도체 팹리스 사피온과 리벨리온의 합병이 VC 업계에서 큰 화두다. KT의 선택을 받은 리벨리온과 SKT의 선택을 받은 사피온의 합병이라는 측면에서도 주목을 끌지만, 팹리스 사이에서 옥석 가리기가 본격화되었다는 점에서도 눈길을 끄는 것 같다. 사피온, 리벨리온, 퓨리오사, 딥엑스 등 AI 반도체 팹리스 스타트업들이 수천억의 Value로 수백억의 투자금을 유치하며 상장을 준비하고 있다.
당장 매출이 많이 나오지 않더라도, 기술력이 높은 평가를 받아 각각의 스타트업들이 수천억의 Value를 인정받았다. 물론, 모두 뛰어난 기업들이고, AI 반도체 시장의 일부를 가져오더라도, 매출은 급격히 뛰어오를 것으로 예상된다. 하지만, 투자 업계에서는 각 기업들이 설계하는 제품들의 장단점이나 기술력을 모두 분석하기보다는 엔지니어들의 이력을 보고 투자하는 경향이 많은 것 같다. 사람만 보고 투자하는 방법은 제품이 나오기 전까지는 어쩔 수 없다지만, 팹리스들이 늘어나는 상황에서 각 업체들이 각자 어떤 concept으로 제품을 설계하였는지 스터디를 해보고 싶어서 국내 AI 팹리스들의 최근 논문들을 Quick-review 해보고자 한다. (참고로, 반도체 설계는 전공 분야가 아니기 때문에, 스터디하면서 쓴 글이니 틀린 부분이 있을 수 있습니다. 본문의 오류를 찾으신다면, 댓글로 수정 요청 해주시기 바랍니다. 전문가 분들의 커피챗은 언제든 환영합니다!)
오늘 리뷰할 논문은 "LPU: A Latency-Optimized and Highly Scalable Processor for Large Language Model Inference" [1]로 Hyperaccel이라는 스타트업의 엔지니어 및 KAIST 김주영 교수님이 쓴 논문이다. LPU (Latency Processing Unit)는 최근 ChatGPT로 핫한 Large Language Model (LLM)을 최소한의 Latency로 돌릴 수 있는 AI 반도체를 일컫는다. Abstract를 보면, "LPU는 Dataflow에 따른 Memory Bandwidth와 Compute의 Balance 조절을 통해, 성능을 최대화한다. 특히, LPU는 Expandable Synchronization link (ESL)이라는 기능을 통해, 여러 LPU 간의 Synchronization latency를 최소화하여, 전체 Latency를 줄여준다."라고 되어있는데, 결국 여러 LPU 사이의 통신 알고리즘 설계를 통해, idle 한 Core를 줄이고, 메모리와 Core를 Flexible 하게 사용하자는 것으로 읽힌다.
Introduction에서는 LLM도 Large model, Small model 등에 따라 성능이 달라지며, 다양한 LLM Application에 Flexible 하게 동작할 수 있는 SW framework를 기반으로 hardware가 동작해야 함을 강조한다. 이 논문의 주요 Contribution은 1) LPU 간의 통신 Expandable Synchronization Link (ESL)을 설계하였다. 2) LLM을 위한 자동 컴파일을 가능하게 하는 SW Framework HyperDex를 만들고, HuggingFace API를 기반으로 제공하는 점으로 보인다. 즉, HW & SW를 모두 최적화하였는데, 최근 반도체는 SW가 절반 이상의 비중이라는 얘기를 많이 듣는 것 같다.
논문에서 지적하는 Conventional GPU의 문제는 "기존 GPU는 병렬처리를 위해 여러 Core에서 Many Thread를 처리하기 위해 설계되었기 때문에, Single Core에 데이터가 가야 할 때 효율적인 데이터 전달이 힘들다."라는 점이다. 이런 문제는 모델이 작을 때 두드러지게 발생하며, SW 기술로 이를 극복하려는 노력들이 있었으나, 앞서 서술한 GPU의 물리적인 한계로 인해, SW 최적화만으로는 Bandwidth Utilization을 어느 수준 이상으로 올리기 힘들다. Utilization이 낮아짐에 따라, Power 측면에서도, idle GPU Core에서 필요 없는 Power 소모도 생기고, 일부 영역에서는 Power가 부족한 (Hungry) 영역도 생기기 때문에, Power 소모 측면에서도 부정적이다.
Nvidia의 GPU에서도 여러 Device (e.g., GPU)가 필요할 때, Device 간의 통신으로 NVLink로 지원하는데, NVLink를 사용하면, 통신 과정에서 Device 간의 데이터 동기를 맞출 때 Latency가 생긴다. 하지만, LPU에서는 Processing 중일 때, 일부 연산 결과물을 미리 Buffer로 빼놓고, 바로 다음 Process를 진행하는 방식으로 Latency를 "Hide"할 수 있다고 주장한다. 얼핏 읽었을 때는 어려운 컨셉은 아닌 것처럼 보이기 때문에, 조금 더 깊게 읽어보기로 했다.
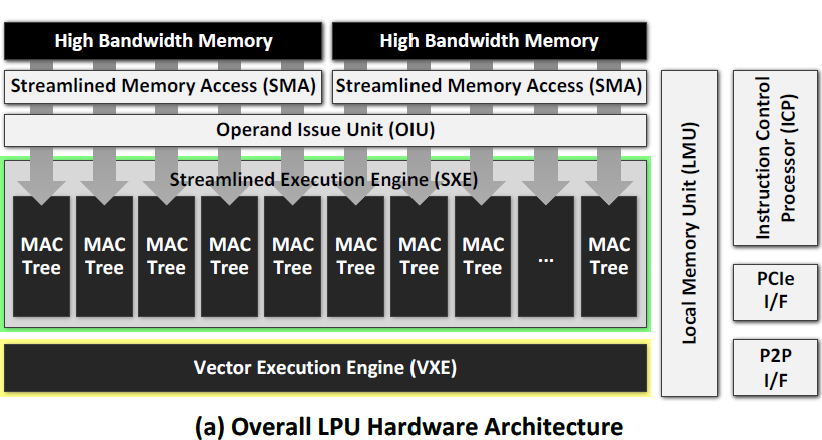
논문의 본문에서 LPU 전체적인 Architecture를 설명하는데, 간략하게 정리하면 다음과 같다. SMA(Streamlyned Memory Access)는 모든 HBM 채널을 실행 엔진에 연결하여 FP16 데이터를 최대 대역폭으로 전송하는 특수 Direct Memory Access (DMA)다. LPU의 하드웨어 인식 메모리 매핑은 SMA에서 데이터 재구성 또는 전환의 필요성을 제거한다. 데이터 재구성 및 전환하는 오버헤드가 어느 정도인지, 모든 HBM 채널을 실행 엔진에 연결한다는 것이 중요한 기술인건지, 기존에는 왜 못했는지 등이 설명되었으면 이해가 좋았을 것 같다. (e.g., HBM 연결될 수 있는 채널 수가 제한적이라거나 인터페이스의 가격 때문이라거나)
OIU (Operand Issue Unit)는 Execution Engine에 넣기 전에 SMA에서 스트리밍 된 데이터(첫 번째 피연산자)와 On-chip Register File에서 입력(두 번째 피연산자)을 중재한다. OIU는 컴퓨팅 명령에 기초하여 Execution Engine을 구성하고 피연산자에 대한 Engine을 결정하는 마이크로코드를 생성한다. Streamlined Execution Engine (SXE)는 Multiply-accumulate (MAC) tree로 이루어져 있으며, LPU의 실제적인 Compute 부분을 담당하고 있으며, MAC tree의 수는 메모리 스피드에 따라 유동적이다. Vector Execution Engine (VXE)는 Token Embedding, Normalization 등의 Vector operation를 수행한다.
ICP (Instruction Control Processor)는 LPU의 전반적인 실행 흐름을 제어하는 RISC 프로세서로, ICP는 주로 명령 버퍼에서 LPU 명령을 가져와 디스패치한다. 반복 및 조건부 로직을 위한 제어 레지스터(e.g., 토큰 및 레이어 번호)를 기반으로 분기 및 점프와 같은 기본 RISC 유형 명령을 실행한다. ICP의 디스패처는 다른 LPU 모듈과 완전히 독립적이므로 제어 간섭을 최소화하기 위해 다른 모듈에서 지침을 지속적으로 프리페칭한다.
Expandable Synchronization link (ESL)에 대한 설명은 조금 더 길게 따로 설명한다. 모델 병렬 처리(e.g., 텐서 병렬 처리)를 채택하는 일반적인 프로세서에서는 Compute가 끝난 후에, 통신이 뒤따른다. ESL에서는 "벡터 행렬 곱셈이 먼저 더 작은 열 기반 작업으로 나뉘어 진행되며", 결과는 P2P 인터페이스의 비트 폭과 일치한다. SXE의 Partial Product 이후의 결과는 레지스터 파일 대신 임시 버퍼로 할당된다. 버퍼에서 지원하는 ESL 데이터 흐름은 다음 작업이 진행 중인 동안 Partial Product를 Peer Device로 즉시 전송할 수 있도록 한다. 이렇게 Compute, Transmit, Receive가 동시에 이루어질 수 있기 때문에, Overlap으로 인한 Latency Hide가 가능해진다. 논문에서는 4개의 LPU 간의 통신을 통해서는 성능이 좋아지지만, LPU가 4개를 넘어가면, 4개 단위로 시스템을 구성해야 최적임을 언급한다.

가장 중요한 것은 이런 방식을 통해서 성능이 얼마나 개선되었는지일 것이다. LPU는 RTL 설계를 위해서 SystemVerilog를 사용하고, Synthesize를 위해서는 Samsung의 4 나노 공정 Library, Synopsys의 Design Compiler를 사용했다. LPU의 Latency를 재기 위해 자체 Cycle-accurate Simulator 사용했다고 하는데, 이 부분은 C++ 기반 자체 Simulator를 사용하였고, 실측이라 보기 힘들기 때문에, ASIC 간의 비교는 조심해서 비교해야 할 것 같다. 이 논문에서는 실측을 위해서 LPU 설계를 Xilinx Alveo U55C FPGA accelerator cards에 얹어서 구현했다. 또한, HuggingFace API로 HyperDex Framework를 적용하여 성능 비교를 했다. 비교군으로는 SOTA GPU 중 하나인 Nvidia의 H100 GPU를 사용하였으며, HBM의 Bandwidth를 어느 정도 맞춰서 Latency 등을 쟀다.
최종 Evaluation에서 Latency는 ASIC 간의 비교를 위해 동사 LPU는 Simulator를 통한 Latency 측정을 한 것으로 보인다. Simulator를 통한 성능상으로는 약 2배의 Speedup이 됨을 볼 수 있다. Chip이 아직 실물로 없는 상황이라 어쩔 수 없었다고는 하지만, 자체 Simulator를 통한 비교라는 점에서 조금 조심해서 숫자들을 비교해야할 것 같다.

FPGA를 사용한 Origin-cloud와 H100 간의 전력 비교를 하면, 약 1.33배의 전력 Save가 가능하며, ASIC으로 비교하면, 더 높은 전력효율을 달성할 수 있음을 강조한다. Device가 더 늘어나면, A100 등 다른 GPU과의 성능 차이가 더 벌어짐을 강조하며, Scalability가 있음을 설명한다. 정리하면, 동사의 C++ Simulator 상으로는 Nvidia의 H100보다 하나의 토큰이 나올 때까지의 시간이 훨씬 줄어듦을 확인할 수 있었다. 또한, 실제 FPGA에 올렸을 때, 전력소모나 Scalability도 있음을 확인할 수 있었다. Simulator도 충분히 의미 있는 비교 방법이며, 실제 FPGA에 올려 비교하였다는 점도 매우 긍정적이지만, 동사가 가장 강조하는 "Latency"에 대한 결과를 실측이 아닌 Simulator로 비교했다는 점이 조금 아쉽다.
기술적으로는 LPU 간의 통신 알고리즘으로 idle 한 Core을 줄이고, 메모리 Bandwidth Bottleneck을 줄여 Utilization을 높이는 기술은 매우 의미 있어 보인다. 하지만, 이런 기술이 경쟁사들이 얼마나 구현하기 어려운 부분이고, LLM를 위한 AI 반도체 연구들과 비교해 보는 것은 어땠을까라는 생각도 드는 것 같다. 예를 들면, 논문의 Related works에 소개된 Groq Language Processing Unit도 LLM inference를 위한 Processor다. Groq도 Llama-2 모델 벤치마크에서 다른 프로세서 대비하여 매우 뛰어난 성능을 보이고 있다고 주장하는데, 동사 Chip과의 비교가 더 있었으면 어땠을까 하는 아쉬움이 있다. 논문에서는, Groq이 16개의 Chip-to-Chip Interconnect와 230MB SRAM을 통합하여 임베디드 애플리케이션을 위한 다용도 옵션을 제공하지만, HBM과 같은 외부 메모리가 없기 때문에 상당한 통신 오버헤드가 발생한다고 얘기한다. 얼핏 들으면, Chip 간 Interconnect와 메모리 최적화가 동사의 LPU와 접근이 조금 유사해 보이는데, 차이점으로 밝힌 HBM 등 외부 메모리는 동사의 기술력이라고 하기에는 애매한 부분이 있고 칩의 가격에도 영향을 미칠 수 있는 이슈이기 때문에, 최근 연구와 더 폭넓은 비교를 했으면 어땠을까 싶다.
또한, 동사의 제품은 HW 설계 (Chip)와 SW Framework (HyperDex)를 모두 사용하여 최적화를 진행하고, 실험을 하였는데, H100 등 비교군은 HW만 최적화하여 비교한 것이 아닌가 싶다. 개인적인 생각으로는 기존 GPU도 HuggingFace에 있는 SOTA infrastructure 최적화 솔루션을 적용하면 성능이 개선될 것 같은데, 해당 비교군과의 실험이 조금 더 옳은 비교가 아닐까 싶다. 또한, Latency에 대해서만 실험을 진행하였는데, CSP 입장에서는 수많은 유저에게 서비스를 제공해야 하기 때문에, 가격이나 Throughput도 매우 중요한 이슈일 것 같다. Latency 감소에만 초점을 맞추다 보면, Throughput이 낮아지는 이슈도 있기 때문에, 조금 더 다양한 지표들로 성능 비교를 해보는 것도 좋을 것 같다.
Conclusion
많은 AI 반도체 팹리스들이 있고, 옥석 가리기가 시작된 현재 시점에서 투자자의 기대는 증폭되었지만 숫자로 증명된 업체는 아직 많지 않다. Value가 높아짐에 따라서 수주가 가시화되거나 실제 AISC으로 구현된 Chip 간의 성능 비교가 어느 정도는 필요하지 않을까 조심스럽게 생각해 본다. 글로벌 기업, 국내 최고 대학교의 교수님들이 리드해서 설계한 반도체인만큼 기술력에 있어서는 매우 긍정적이라 생각한다.
HyperAccel은 개인적으로 관심 있게 보고 있는 스타트업이기 때문에, 본 글 말미에 개인적으로 궁금한 포인트들을 조금 많이 적었는데, 나의 이해력이 부족해서일 수도, 핵심 기술은 공개하기 힘들어서일 수도 있다. 단, 실제 ASIC으로 만들어서 성능 비교를 한 것은 아니고, 하이퍼엑셀에서 원하는 설계가 높은 수율로 구현가능할지는 추가 검증이 필요해 보인다. 지금부터 디자인하우스에 의뢰하고 파운드리에서 칩을 받는다 해도, 엔비디아는 H100을 넘어서는 성능을 가진 블랙웰의 수율을 잡는 중이기 때문에, 엔비디아의 개발 및 제품 출시 속도를 따라잡을 수 있을지는 모르겠다. 이렇게 막대한 자본을 투입한 글로벌 반도체 업체들의 최첨단 반도체 성능과 비교하여 절대 우위를 보이기는 어렵지 않을까 조심스럽게 추측하며, 협업 중인 업체들에서 일부 물량이 나올 수는 있지 않을까 생각한다. 공개된 논문의 정보와 나의 이해 수준 내에서 쓴 글이지만, Hyperaccel의 LPU가 고객사가 요구하는 여러 Requirement를 모두 만족하여, 글로벌 대기업들의 수주를 받을 수 있기를 바란다.
Reference
[1] Moon, S., Kim, J. H., Kim, J., Hong, S., Cha, J., Kim, M., ... & Kim, J. Y. (2024). LPU: A Latency-Optimized and Highly Scalable Processor for Large Language Model Inference. IEEE Micro.
[2] D. Abts et al., “A software-defined tensor streaming multiprocessor for large-scale machine learning,” Proceedings
of the 49th Annual International Symposium on Computer Architecture (ISCA)., pp. 567–580, 2022