-
Video Coding for Machine (VCM) 논문 리뷰최신 기술동향 2021. 7. 13. 18:08
이번에 리뷰할 기술은 Video Coding for Machine (VCM)이다. 일반적으로, 이미지를 압축한다고 할 때는 JPEG, 영상을 압축한다고 할 때는 H.264 등의 압축 표준을 사용한다. 전통적인 압축의 방식은, 어느 정도 데이터(e.g., 이미지, 영상)가 뭉개져 보이는 형태더라도, 사람이 보기 쉽게 Encoding이 된다. 예를 들면, JPEG으로 압축된 데이터를 사람이 본다고 했을 때, 비행기인지, 새인지 판단할 수 있다. 이런 기존의 압축 방법 덕분에, 우리는 몇십 MB에 달하는 이미지 한 장, 몇십 GB에 달하는 영상 하나를 수십 배까지 용량을 줄여서 전송할 수 있었고, 이렇게 압축된 데이터가 다양한 use case에 적용되었다.
하지만, 클라우드 컴퓨팅을 위해 해당 데이터를 전송해야 하는 상황을 가정해보자. Cloud Computing에서 돌아가는 Application은 다양하게 있을 수 있지만, 가장 간단하게, 영상을 보고 사람의 얼굴을 Detection 하는 App이 돌고 있다고 가정한다. 이때, Cloud에 있는 Neural Network (NN) 모델은 자신한테 들어온 Input이 '인간이 알아보기 쉬운 형태인지'는 관심이 없다. 쉽게 얘기하면, 인간에게 적합한 Input 포맷이 있고, Machine에게 적합한 Input 포맷이 있다는 얘기다. 사람이 직접 보고 판단해야 하는 경우라면, 전자가 적합하겠지만, Machine이 판단을 해야 하는 상황이라면 후자가 적합하다. 후자의 경우에는 인간을 위해서 불필요하게 들어갔던 데이터들이 사라지고, 핵심만을 요약하기 때문에 더 효율적인 압축이 가능해진다. 점점 AI가 고도화될수록, AI가 알아보기 쉬운 형태의 Data Compression에 대한 필요성이 부각되었고, 이를 Video Coding for Machine (VCM)이라 하여, 동영상 압축 표준을 논의하는 Moving Picture Experts Group (MPEG)에서 이에 대한 본격적인 논의를 시작하여, MPEG-VCM 기술이 연구되고 있다.
더 높은 Frame rate, 더 높은 Accuracy 등 좋은 Performance를 보이기 위한 기술들이 여러 논문들을 통해 제시되고 있다. Survey 형태의 논문을 통해 기술의 트렌드를 전체적으로 다뤄보고자 한다.
제목: Video Coding for Machine: A Paradigm of Collaborative Compression and Intelligent Analytics [1]
저널명 : IEEE Transactions on Image Processing
출판년도 : Jan, 2020
저자 : Ling-Yu Duan, Jiaying Liu, Wenhan Yang, Tiejun Huang, Wen Gao
Introduction
Video와 Image 데이터가 쏟아지면서, Compress와 Analyze에 대한 연구가 많이 진행되고 있다. 지난 수십 년간, 기존의 압축 방식들 (MPEG-4, AVC/H.264)와 High Efficiency Video Coding(HECV), Audio Video coding Standard (AVS) 방식등이 좋은 성능을 보여줬다. 이 방식들은 주로, Pixel 간의 Spatial-temproal 특성을 이용해 Redundancy를 제거하는 방향으로 알고리즘이 구성되어 있다. 이 방법들은 육안으로 봤을 때, 사람들이 인식할 수 있는 형태로 압축이 되는데, 최근, Deep Learning을 이용한 압축 방식등이 제안되고 있다. Effective Compression은 단순히 데이터의 크기를 줄여서 Bitstream으로 보내는 것이 아니라, Feature Descriptor라는 information으로 Feature를 함께 전달하여, Decoder에서는 이런 Feature Descriptor를 함께 사용해서 Decoding을 수행한다. MPEG에서는 Compact Descriptor for Visual Search (CDVS)와 Compact Descriptor for Video Analysis (CDVA)라는 표준을 제정함으로써 효율적인 Video Compression 방식을 표준화했다. 이 부분은 어떻게 보면 당연하다고, 할 수 있는 게, Feature를 뽑는다는 과정 자체가, 해당 데이터를 대표하는 최고의 압축 방법이기 때문에 더 효율적인 압축이 가능할 것으로 보인다.
전통적인 방식의 Video Coding에서 자주 언급되는 Intra-Prediction과 Inter-Prediction은 Temporal/Spatial Redundancy를 줄이기 위한 방법으로 Reconstruct와 Motion Compensation을 위해 35개의 Mode 중에 하나가 선택되어야 한다. Rate-Distortion Optimization (RDO)라는 방식으로 최적의 Mode가 선택이 되는데, Signal Distortion과 Bitrate간의 Trade-off를 고려하여 여러 최적화 문제에 자주 사용되는 Lagrangian Optimization으로 고른다.
Deep Learning을 이용한 방식이 2015년 이후로 등장했는데, Auto-Encoder 형태, PixelCNN 등의 Deep Learning Model에 익숙한 사람들은, 이미 AI로 이미지를 압축할 수 있다는 생각을 했을 것으로 생각된다. 기존의 방식들이 Partition을 쪼개서 Compression을 진행했다면, Deep Learning은 조금 더 넓은 영역을 돌아다니면서, Feature Extract를 진행한다. 이 과정에서 자주 등장하는 R-D cost는 앞서 소개한 Rate-Distortion에 대한 Metrics로, 보내는 Bits 대비해서 얼마나 Distortion이 생기는지에 대한 성능지표다. 당연한 소리지만, 원래 데이터를 보내면, Distortion이 없지만 Rate는 크고, Compression을 많이 할수록, Distrotion은 많이 생긴다. 이 중간에서 적절한 포인트를 잡아서 최고의 성능을 내는 것이 모든 알고리즘의 핵심이라고 할 수 있다. VCM 또한 Video Data를 주고받음에 있어서, 적은 bits를 보내고도, 좋은 성능을 내고자 하는 알고리즘이다. 단, 인간이 인지하기 쉬운 형태가 아니라, Machine만 이해해도 되는 형태로 보냄으로써 Redundancy를 줄이고, bits를 적게 보내도 되게 만들어보자는 기술이다.
Video Coding for Machine (VCM)
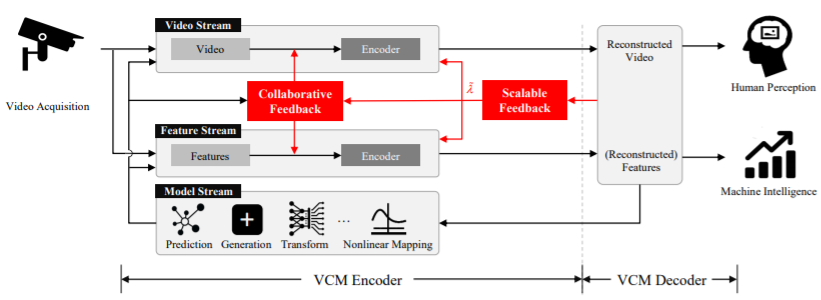
Fig. 1, Video Coding for Machine (VCM)의 구조도 그러면 정확하게 VCM이 의미하는 것이 무엇일까? 기존의 CDVS, CDVA방식은 어떤 특정 Task를 위한 Feature들을 주고 받기 때문에, Specific Task에 상당히 Dependent 한 것을 알 수 있다. 반대로, HEVC 등의 고화질을 위한 압축 방식은 Video 등의 대규모 데이터를 효율적으로 압축하는데 취약하다. 이 논문에서는 Fig. 1을 통해, VCM의 구조를 설명하고 있다. Fig. 1에서 보는 구조에서는 카메라를 통해 들어온 Video 데이터가 Human을 위한 첫 번째 Block과 Machine을 위한 2 번째 Block으로 같이 들어간다. 두 개의 Block으로 들어가서 Encoding 된 Video Stream과 Feature Stream은 Decoder에서 Reconstruct 되고, 여러 Task의 성능을 joint optimize 하기 위해 두 블록에 Feedback이 들어가서, bits는 줄이고, 성능은 최대화하는 시스템이 구성된다. 결국, Multi-task의 중요도를 파악하고 Feedback 해서, 각 Encoder의 Computation, bits 등을 함께 조절하겠다는 의미다.
이런 Task에는 Object Detection, Video Prediction and Generation 등이 포함된다. Time축 성분을 뽑아내기 위해 LSTM, GRU 등의 RNN 계열 모델이나 Spatial Feature를 뽑아내기 위한 CNN 계열 또한 쓰인다. 이렇게 다양한 Deep Learning Model을 통해 Low-Level, High-Level Feature를 뽑아내서 Fig. 2처럼 각각의 Task에 사용하게 된다.
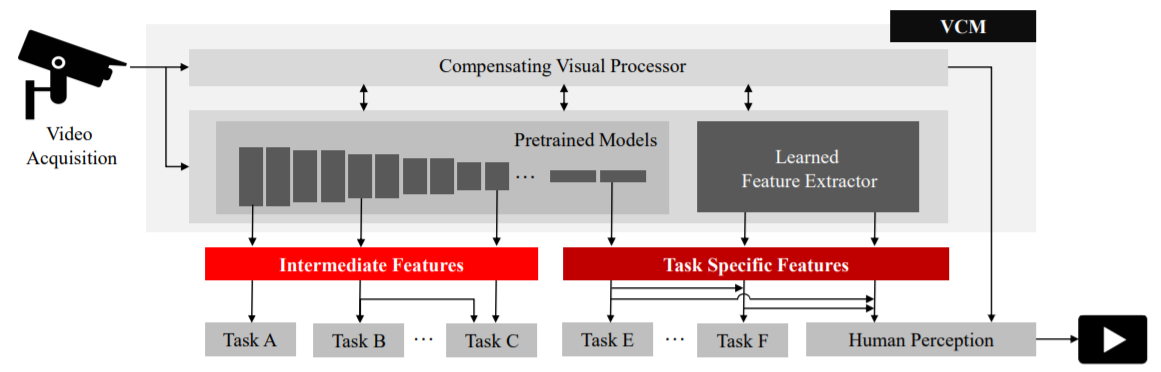
Fig. 2 VCM의 Key Module Fig. 2에서 볼 수 있듯이, Pretrain된 Model의 여러 Layer에서 Extracted Feature가 나오는데, 각 Task가 이를 이용하게 된다. Deep Layer에서 조금 더 구체적인 Feature가 많이 나오기 때문에, Task-specific 하다. Human Vision은 이 중 마지막 Layer에서 나온 Feature를 통해 복구하는 경우가 많다. 이런 방식들을 통해, Action Recognition 등의 Task에서 기존의 Compression 방식 HEVC 대비 더 적은 Bitrate로 더 높은 Accuracy를 보이는 결과도 있다. 한 가지 문제점은, overfitting이 되었을 때, 성능이 전통적인 방식보다 불안정할 수 있다는 점이기 때문에, 많은 데이터를 필요로 한다.
Conclusion
이 논문을 리뷰하고, ETRI에 소개된 Technical Report를 통해 동향을 분석하면서 VCM의 필요성과 구조에 대해 공부할 수 있었다. 전체적으로 Bitrate를 줄이면서, AI를 통한 Analytics의 성능을 높이고자 하는 목적을 갖고 있는 이 기술은 앞으로 AI를 통한 기술이 더욱 발전하고, Video Analytics를 활용할 수 있는 여러 Use Case들이 발굴되고 있는 현재 트렌드에서 빛을 볼 것이라 기대한다.
Reference
[1] Ling-Yu Duan,Jiaying Liu, Wenhan Yang, Tiejun Huang, Wen Gao "Video Coding for Machines: A Paradigm of Collaborative Compression and Intelligent Analytics", IEEE Transactions on Image Processing, Jan, 2020.
반응형'최신 기술동향' 카테고리의 다른 글
Non-Fungible Token (NFT)의 개념과 견해 (1) 2021.11.06 Intel의 Neuromorphic Chip - Loihi 2 (0) 2021.10.11 Neural Processing Unit (NPU)의 기술 및 시장 동향 (1) 2021.10.09 Ultra-WideBand (UWB) 기술의 원리와 Use case (0) 2021.08.15 Forbes IT 기사 리뷰 - Google's Tensor SoC (0) 2021.08.10