-
Meta-Learning과 MAML의 개념 정리최신 기술동향/인공지능 (AI) 2021. 9. 19. 19:42
이번 글에서는 최근, 그 중요성이 점점 부각되고 있는 Meta-Learning에 대해 정리해보려고 한다. Meta-Learning은 다른 Task를 위해 학습된 AI 모델을 이용해서, 적은 Dataset을 가지는 다른 Task도 잘 수행할 수 있도록 학습시키는 방식이다. Meta Learning이 각광받는 가장 큰 이유는 모을 수 있는 Data의 양이 적다는 점과 HW의 Limitation이다. Deep Learning의 대부분 Application은 많은 Data를 High Computational HW에서 Training해서 좋은 성능을 보인다. 하지만, 대부분의 Application은 고품질의 Data를 모으기도 힘들고, 이를 Training할 Computational Power도 부족한 상황에서 적용되어야 한다. 따라서, 주어진 환경에 맞게 Re-Train하는 알고리즘들이 부각되고 있고, 공부하다보면, Transfer Learning, Meta-Learning, Multi-task Learning, Continual Learning 등 다양한 이름들이 등장한다. 공부하면서 많이 헷갈렸던 부분들이고, 다 중요하게 거론되는 알고리즘들이라 이번 기회에 Meta-Learning과 다른 알고리즘 들과의 차이도 같이 정리해보려고 한다. 단, 소개된 알고리즘이 딱딱 나눠떨어지는건 아니고, 포함관계나 겹치는 부분이 많다는 점을 참고하길 바란다.
가장 먼저 Multi-task Learning과 Meta-Learning을 비교해보면, Multi-task Learning은 각 Task가 최적의 Parameter $\phi$를 공유하는 형태로 이루어진다. 즉, 하나의 커다란 Model이 다양한 Task를 지원할 수 있는 형태로 이루어지고, 새로운 Task의 Dataset이 들어오면, 다수의 Task에 동시에 최적화된 Model의 Parameter $\phi$를 찾기 위해 학습을 하는 방식이다. 하지만 Meta-Learning은 각 Task 마다 최적의 Parameter $\phi_i$가 다르다는 Assumption부터 시작하기 때문에, 기존에 학습된 모델의 Parameter $\phi$와 새로운 Dataset의 특성 사이의 Correlation에 대한 새로운 Parameter $\theta$를 찾는 과정을 통해, $\theta$에서 새로 들어온 Task의 $\phi$를 찾는 순서로 진행된다.
Transfer Learning과 Meta-Learning은 둘 다 Few-shot Learning을 위해 제안된 알고리즘이다. 하지만, 서로 배타적으로 나뉜 알고리즘은 아니고, 'meta-learning as belonging to transfer learning approaches'라고 소개하는 논문 [1]도 있다. 단, 이 논문에서 '편의를 위해 분류를 하면서', Transfer Learning은 조금 더 Pre-trained 모델을 기반으로 적은 Dataset을 기반으로, Fine-Tuning하는 알고리즘이라는 점에 초점을 맞추고, 기본적으로 조금 더 많은 Dataset이 필요하다는 얘기를 한다. 하지만, Meta-Learning은 말 그대로 'Learning-to-Learn'이라는 Concept처럼, Hand-design의 느낌이 나는 Transfer Learning보다 '빠르게 Adaptation할 수 있는' 최적의 알고리즘을 찾기 위해 제안되었다고 소개한다. 정리하면, Meta-Learning이 더 적은 Dataset을 Targeting하여, 빠르게 최적화가 이루어질 수 있도록, Generalization에 Focusing이 되어있는 방식이라고 정리할 수 있을 것 같다.
Meta Learning은 크게 Model-based model, Metric-based Approach와 Optimization-based Approach으로 나눌 수 있는데, Metric-based Approach 저차원의 공간에 새로 들어온 데이터를 Mapping시키고, 저차원에서 '데이터 간의 거리'가 가까운 방향으로 새로운 Task의 Dataset을 Classification하는 알고리즘이다. 하지만, Classification 이외에도 Reinforcement Learning 등 다양한 알고리즘에도 적용가능하다고 알려진 Model-Agnostic Meta-Learning (MAML) [2]이 주목을 받고있다. 이 글에서는 MAML과 이 알고리즘이 속한 Optimization-based Approach를 중점적으로 설명한다.
Optimization-based Approach의 Concept을 쉽게 설명하면, 여러 Task의 generalized 버전 Model의 Parameter인 $\theta$를 구하고, 이를 new Task Model의 Parameter인 $\phi$의 Initialization으로 정의한다. 이렇게 함으로써 최적의 Task Parameter $\phi^*$를 빠르게 찾아나갈 수 있다.
Model-Agnostic Meta-Learning (MAML)
MAML은 [2]에서 소개된 논문으로, Meta Learning에서 가장 중요한 논문 중 하나인데, 주목받는 이유는 이름에서 알 수 있듯, 'Model-Agnostic (모델과 상관없이)'하게, 즉, 대부분의 AI모델 (e.g., supervised Learning, reinforcement Learning) 에 적용될 수 있기 때문이다. MAML에 대한 대략적인 설명은 Multi-task Learning과 Meta-Learning을 비교하면서, 많은 부분을 설명했기 때문에, 바로 알고리즘을 분석해보려고 한다.
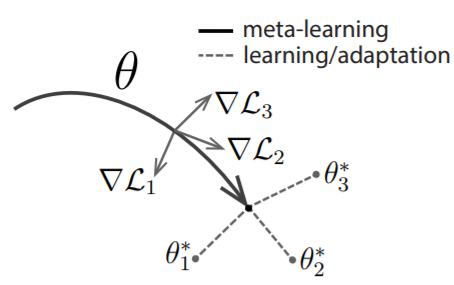
MAML의 Diagram MAML의 Diagram은 위와 같다. Meta-Learning은 결국 Generalized Model의 Parameter인 $\theta$를 찾아나가는 방식으로 Gradient Descent를 진행한다. 위 그림에서 $\theta$가 가리키는 point가 Task 1, 2, 3에 대한 최적은 아니지만, 이후, Task 1, 2, 3을 빠르게 Adaptation할 수 있는 point이기 때문에 Meta Parameter $\theta$가 위의 화살표가 가리키는 점으로 가게되는 것이다. 이후, 얻은 $\theta$에서 new Task $T_i$에 맞는 최적의 Model Parameter $\theta^*$를 찾아가는 방식으로 Gradient Descent를 진행한다. 위에서는 자세한 알고리즘은 아래 그림과 같다.

MAML의 알고리즘 처음에 Model은 $\theta$로 Initialized가 되어있다. $p(T)$는 전체 Task set이라고 보면 되고, new Task $T_i$에 있는 datapoint로 학습을 진행한다. Supervised Learning에서 Regression인 경우에는 (2)의 Mean Square Error (MSE)를, Classification의 경우에는 Cross Entropy를 Loss function으로 사용하여, 이를 기반으로 Gradient Descent를 진행한다. 그러면 Initialized 되어있는 $\theta$가 $\theta^{new}$으로 update가 되는데 (line 6), 한 두번의 Gradient Descent만 필요하도록 조정한다고 한다. 이렇게 구한 $\theta^{new}$를 기반으로 다시 Generalized model의 Parameter인 $\theta$를 조정해야한다. 새로운 New Task $T_i$를 한 두번의 Gradient Descent로 optimize하려면, 'Meta-optimization across Tasks'를 진행해야하고, 이 값은 우리가 구한 $\theta^{new}$를 기반으로 Gradient Descent를 진행한다. 이 과정을 반복하면서, Few shot Learning이 지속적으로 이루어질 수 있게된다.
Supervised Learning에 대한 알고리즘은 Loss Function만 Cross-Entropy와 MSE로 바뀌었기 때문에, 이해하기 어렵지 않고, Reinforcement Learning (RL)에 적용하는 알고리즘에 대해 보도록 하자. Supervised Learning에서 Regression과 Classification을 위한 Model이 주를 이룬다면, RL은 Expected Reward를 기반으로 Action을 결정하는 Policy에 대한 학습 알고리즘이다. 즉, RL에 Meta Learning을 적용한다는 것은, Task가 변하는 환경에서, 적은 Experience로 Policy를 Update하는 방식이라고 생각하면 된다. 이 논문에서는 하나의 Maze (미로)에 특화된 알고리즘이 다른 Maze 탐색에 활용될 수 있다고 소개한다.

MAML for Reinforcement Learning RL과 Supervised Learning 알고리즘의 차이는 $K$개의 Sample이 $K$개의 Trajectory로 바뀌었다는 점과 Expected Reward가 Loss Function에 반영이 된다는 점이고, 나머지는 거의 똑같다. Policy Gradient은 학습하는 Policy와 Action하는 Policy가 같은 On-Policy 방식이기 때문에, 새로운 Policy의 Parameter $\theta$를 구할 때, update된 Policy $\theta^{new}$에서 Sampling을 한다. 이후에 나오는 Experimental Evaluation은 당연하겠지만, Few Shot Training의 경우, MAML을 쓰면 다른 Fine Tuning 알고리즘에 비해 성능이 좋다라는 결과들이 첨부되어 있다.
Conclusion
이번 글에서는 Meta-Learning, 그 중에서도 가장 유명한 알고리즘인 MAML 논문 [2]에 대해 정리했다. 딱 보기에도, 그닥 개념적으로 어렵지 않고, Model-Agnostic하다는 장점 때문에 모든 Meta-Learning 논문의 뼈대가 되어서 인용수가 많지 붙지 않았나싶다. (2021.9.20 기준 4,339회) 하지만, Meta-Learning에서 말하는 '비슷한 Task'가 어느 정도로 비슷해야 하는지, Gradient Descent는 몇번으로 해야하는지, Few shot이라는게 몇 개정도의 Sample을 의미하는지 등 애매한 부분이 없지 않다. 물론, Domain에 따라 달라지겠지만, 환경이 끊임없이 변하는 비슷한 Task에서는 큰 힘을 발휘할 수 있지 않을까라는 생각이 든다. 후속으로 나오는 Meta-Learning에 대한 Survey 논문 [3]과 이를 활용한 주요 논문들을 읽으면서, 활용 방안에 대해 조금 더 고민해볼 여지가 있을 것 같다. 이 다음 글로는 5G에 Meta-Learning을 적용하는 논문 [4] 을 리뷰 [5]할 예정이다.
Reference
[1] Vincent Dumoulin, Neil Houlsby, Utku Evci, Xiaohua Zhai, Ross Goroshin, Sylvain Gelly, and Hugo Larochelle. Comparing transfer and meta learning approaches on a unified few-shot classification benchmark. arXiv preprint arXiv:2104.02638, 2021.
[2] C. Finn, P. Abbeel, and S. Levine. Model-agnostic metalearning for fast adaptation of deep networks. In International Conference on Machine Learning, 2017.
[3] T. Hospedales, A. Antoniou, P. Micaelli, and A. Storkey, “Metalearning in neural networks: A survey,” 2020, arXiv:2004.05439. [Online]. Available: http://arxiv.org/abs/2004.05439
Meta-Learning in Neural Networks: A Survey
The field of meta-learning, or learning-to-learn, has seen a dramatic rise in interest in recent years. Contrary to conventional approaches to AI where tasks are solved from scratch using a fixed learning algorithm, meta-learning aims to improve the learni
arxiv.org
[4] Y. Yuan, G. Zheng, K. -K. Wong, B. Ottersten and Z. -Q. Luo, "Transfer Learning and Meta Learning-Based Fast Downlink Beamforming Adaptation," in IEEE Transactions on Wireless Communications, vol. 20, no. 3, pp. 1742-1755, March 2021, doi: 10.1109/TWC.2020.3035843.
[5] https://engineering-ladder.tistory.com/96
Meta-Learning Based Beamforming 논문 리뷰
인공지능 카테고리에 Meta-Learning에 대한 글 [1]을 정리하면서, 환경이 급변하는 여러 Domain에 Meta-Learning이 적용될 수 있다는 가능성으로 글을 시작하고 맺었다. 이번 글에서는 여러 Use cases 중에 '
engineering-ladder.tistory.com
반응형'최신 기술동향 > 인공지능 (AI)' 카테고리의 다른 글
Object Detection Algorithm (Efficientdet) (0) 2022.05.01 Nimble: Parallel GPU Task Scheduling for DL - NIPS 논문 리뷰 (0) 2021.11.13 Continual Learning의 원리와 연구 Trend (2) 2021.09.17 TRPO와 PPO 알고리즘의 개념 (0) 2021.09.06 Google AI Blog(논문) 리뷰: SoundStream (An End-to-End Neural Audio Codec) (0) 2021.08.14