-
Policy Gradient Algorithm최신 기술동향/인공지능 (AI) 2020. 8. 13. 10:51
대부분의 강화학습 알고리즘 구조는시행을 반복하며, Agent가 받을 Expected Reward를 최대화하는 방식으로 Training이 이루어진다. 대부분의 Model-Free 알고리즘들은 확실한 Model과 Reward를 알지 못하는 상태에서 Environment (환경)과의 상호작용을 하며 Episode를 여러 번 진행하면서, Reward를 받고, 이를 통해 자신의 Policy를 update시켜 나간다.
강화학습에는 크게 Value-Based RL과 Policy-Based RL이 있다. Value-Based RL은 가치함수인 Q-value를 계산하고, 이를 이용해 action을 선택하는 과정을 반복함으로써 Expected Reward를 최대화하는 방향으로 구현하는데, 대표적으로 Q 함수에 Neural Network를 적용하는 DQN이나 Dueling Network 등이 있다. Policy-Based RL은 Parameter θ로 이루어진 Policy를 가지며, 이 Policy를 구성하는 Parameter를 control하여 Reward를 최대한 방향으로 구현하는데, 최근에 나오는 많은 모델들이 Policy-Based모델을 기반으로 하고, 대표적으로, Actor-Critic, A3C, TRPO, PPO 등이 있다.
DQN이 Q value에 DNN을 적용하여 Approximation하여, Continuous한 State에서도 적용할 수 있게 된 것처럼, Policy-Based에서는 Continuous한 Action에 적용될 수 있다. Policy 자체를 학습시키기 때문에, Continuous한 Action을 다룰 때도, 이에 맞는 Action의 분포가 나오게 된다. 더 나아가, Value-Based에서는 Value Function이 조금만 바뀌어도 Policy가 급격하게 바뀌는 것과 비교했을 때, Policy-Based에서는 Policy가 smooth하게 update되기 때문에 Stable하다.
개인적으로 Reinforcement를 5G 등 통신에 적용시킨 논문들을 보면, 여러 User간의 Interference를 Minimize하기 위해 Power level을 discrete한 Level에서 고르는 방법 등 선택할 수 있는 Action이 적으면 DQN을 많이 사용한다. SINR값을 Input으로 넣다보니, State는 Continuous한 상황을 고려한 것으로 보인다. 하지만, 한 번에 하나의 Action을 취하는 것이 아닌, 여러 Action을 복합적으로 선택해야 하거나 (e.g., V2V의 Link, Power, mode 등을 함께 Control하는 경우) Continuous한 Action을 해야하는 경우에는 Action의 수가 너무 많아진다. 이 때는 Policy-Gradient에서 가장 많이 알려진 Actor-Critic을 사용하는 논문이 많은 것 같다. DQN을 적용한 논문이 더 많은 것으로 보이지만, 개인적으로는, 여러 Action을 같이 Control하거나 Continuous한 Action을 다루는 Policy Gradient Algorithm을 적용하는 것이 성능 측면에서 더 좋을 것으로 생각한다. 이번 리뷰에서는 Policy-Gradient에 대해서 더 알아본다.
Policy Gradient Method
Policy Gradient는 Objective Function의 Gradient를 따라서 Policy를 이루고 있는 parameter θ 를 조금씩 바꿔가면서 Policy를 optimize / Update한다. 그러면, 여기서 Objective Function을 어떻게 잡는지에 대해서 조금 더 생각해봐야한다. Deep Learning에서 사용하는 많은 Objective Function은 실제 값과 예측 값을 알려주기 때문에, 정답과의 차이를 반영한 Root Mean Squared Error(RMSE)나 분류모델의 Cross Entropy 등을 사용한다. 하지만, 강화학습에서는 정확한 답인 '실제 값'을 Deep Learning처럼 먼저 줄 수 없기 때문에, 조금 다르게 생각할 필요가 있다.
Objective Function은 말 그대로 '우리가 최적화 하기 원하는 함수'이기 때문에 강화학습의 목적인 ' Expected Reward의 최대화'를 기준으로 생각하면 된다. 따라서, Policy Gradient의 기본적인 Objective Function은 다음과 같다.

Policy Gradient의 Objective Function 이렇게 Expected Reward에 관한 Objective Function을 기준으로 잡았고, 기본 Reinforcement Learning 알고리즘이냐, Actor-Critic이냐 등의 알고리즘에 따라서, 다양한 Policy Gradient (PG) 값들이 있다. 주어진 Environment는 같더라도, 최적의 Policy를 찾아나가는 알고리즘은 다르기 때문에 이에 따라서 PG가 다르다.

Policy Gradient Objective Function을 미분한 Gradient는 위와 같은 형태를 갖고 있는데, 강화학습의 특성상 Policy가 조금 변하는 것만으로도 큰 Variance 변화가 생기기 때문에 이를 보완하기 위한 다양한 방식이 제안되고 있다.
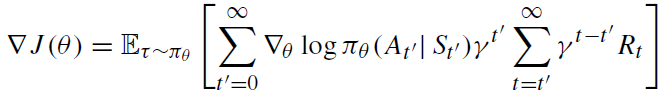

위와 같이, Episode 후반부에 나오는 Variance를 줄이기 위해, 후반부에 Discount factor를 곱하기도 하고, Early state의 Variance를 줄이기 위해 앞에 곱하기도 한다. 또는, Action이 아닌, state에만 영향을 받는 'baseline'을 Reward term에서 빼서, 전체 Variance를 줄이기도 한다. 이런 Baseline을 어떻게 설정하는 것이 좋을지에 대한 논문도 2017년부터 많이 Propose되고 있다. 주로, V(S)같이 State Value Function을 잡는 경우가 많다.
Actor-Critic
Actor-Critic (AC)는 Policy의 Parameter θ를 update시키는 'Actor'와 Value Function을 update시키는 'Critic'으로 이루어져 있다. Actor가 Action을 하고, θ를 update시킨 후(Policy Update), Critic에게 update된 Policy를 주면, Critic은 updated된 Policy를 평가하여, Value Function의 parameter w를 update하고, updated Value Function을 Actor에게 넘겨준다.
Critic은 Value Function을 update하기 위해 L-step TD error를 이용한다. 즉, 예측치와 실제 L-Step을 시행해 본 결과값을 비교하는 L-step TD error를 minimize하는 방식으로 Value Function을 update한다. 실제 구현에서는 L-Step을 1-step으로 주로 사용한다.
Actor는 State S를 input으로 받아서 Policy, Action을 output으로 내보낸다. 이 때, Critic이 update해서 넘겨준 Value Function와 Policy Gradient를 통해 Policy parameter θ 를 update 시킨다. Update한 Policy를 Critic에게 넘겨주면, Critic은 이를 이용해서 또 Value Function을 update한다. 이렇게 Actor와 Critic가 update를 반복함으로써 성능 향상을 이끌어 낼 수 있다.
Synchronous Advantage Actor-Critic (A2C)
2016년에 나온 A2C는 Actor-Critic과 매우 유사하지만, Parallel training에 초점을 둔 알고리즘이다. 여러 Workers가 각자 Environments와 Interact하면서 Reward와 다음 state를 받아온다. 이를 Master Node에 있는 Actor-Critic 모델에 주면, Master Node의 Actor-Critic에서 Update를 해서, Updated Value, Updated Policy를 Workers에게 내려주고, 이 Policy, Value를 기반으로 Worker들은 다음 Action을 진행하게 된다. 단, 이 경우 Master Node에 너무 Load가 커질 수 있기 때문에, Worker에서 Gradient 계산까지 해서, Master에게 넘겨주면 Master에서는 Gradient를 취합하고, Update해서 내려주는 방식도 있다.
Asynchronous Advantage Actor-Critic (A3C)
A2C에서 Coordinator가 각 Worker에서 들어오는 Policy Gradient 값을 모아서 한번에 Master에게 주었다면, A3C에서는 Coordinator가 없다. 따라서, 먼저 계산한 Worker가 결과값을 Master에게 넘기면 Master가 바로 바로 update를 해서 넘겨준다. Compuation 효율면에서는 더 좋아지겠지만, Sync가 안 맞기 때문에, Worker에서 넘겨준 Gradient값이 Global Actor-critic의 Gradient값과는 다를 수 있다.
Trust Region Policy Optimization (TRPO)
위에서 소개한 알고리즘들은 모두 Objective Function에 대한 1차 편미분을 해서 Policy parameter θ를 update했다. 그런데, PG에 곱해주는 Step Size를 너무 크게 하면, 오히려 Reward에 악영향을 미칠 것이고, 너무 작게하면 Train 되지 않을 것이다. 이는 Deep Learning에서도 Learning Rate를 어떻게 설정할지 고민하는 것과 비슷하다. 또한, Parameter에 따라서 Step size의 영향이 크게 차이 나는 점도 문제로 꼽힌다.

Parameter Update TRPO는 Step-Size에 따라서 불안정적으로 Training이 되는 것에 대한 해결을 제시한다. 요약하자면, 'New policy를 Improved performance로 update한다고 믿을 수 있는 지역 (Trust Region)에서만 update하자'는 주장이다. 즉, Policy Update가 향상시킬 수 있다고 보장은 할 수 없지만, 적어도 '악화는 시키지 않도록 하자'는 내용이다. Old Policy에서 Updated Policy로 바뀌면서의 Improvement를 Advantage Function이라고 한다. (Kakade and Langford 2002). 그런데, 이 수식을 한번에 New Policy에 대해서 update하는 것이 수식적으로 까다롭기 때문에,

이런 근사화를 통해서, 최적화 함수를 변환한다. 처음 수식은 updated policy를 따라가면서 (Trajectory), 최적화를 해야하기 때문에 바로 updated policy를 찾기 힘들지만, 근사화를 통해 old policy를 따라가면서, 최적화를 진행하면, 기존에 있는 Policy로도 최적화가 가능해진다.
그러면, 내 맘대로 근사화를 해도 문제 없을까? 문제 없다는 증명도 친절하고 복잡하게 해준다. 이에 대한 근거를 다루는 내용이 'Bound'에 대한 설명이다. 기존 함수와 approximated된 함수가 '우리가 관심있는 영역'에서 일정 Bound를 넘어가지 않는다는 조건을 만족하면 근사할 수 있다. 따라서 다음과 같은 TRPO 최적화 식을 가지게 된다.

TRPO 최적화 식 깊게 들어가면, 필요한 내용들이 매우 많지만, 이 부분은 조금 더 정리해서 별도의 TRPO 정리에서 다룰 예정이다.
Proximal Policy Optimization (PPO)
PPO는 TRPO에서 Approximation으로 인한 Contraint를 더 깔끔하게 정리한 버전이다. PPO-penalty Algorithm에서는 contraint 대신 penalty term을 objective function 하나의 식으로 반영하였다.

PPO Penalty 또 다른 방법으로 더욱 Consevative (보수적)으로 업데이트할 수 있는데, 이 알고리즘에서는 Clipping이라는 '문제가 생기는 부분을 잘라버리는' 방법을 통해서 해결한다.


PPO-Clipping 이를 통해서, 너무 많이 벗어나는 부분에 대해서는 Clip을 통해서 상한, 하한선을 반영할 수 있다.
Conclusion
가장 많이 언급되는 Policy Gradient Algorithm들을 정리해보았다. 이 글에서는 정말 짧게 개념만 소개했지만, 논문을 열어보면 상당히 어려운 수식들이 많이 나와있다. 시간이 허락한다면, 관련 논문들을 하나씩 정리할 계획이다. 그런데, 모든 수식을 알지 못해도 5G나 기타 여러 환경에 적용할 수 있을 것으로 보인다.
https://stable-baselines.readthedocs.io/en/master/index.html
Welcome to Stable Baselines docs! - RL Baselines Made Easy — Stable Baselines 2.10.1 documentation
© Copyright 2018-2020, Stable Baselines Revision e54554d8.
stable-baselines.readthedocs.io
위와 같은 여러 Tool들을 통해서, 단순히 알고리즘(TRPO, PPO 등)을 불러오는 것도 가능하다. 여러 글이나 논문을 통해 대략적인 감을 잡고, 모델 안에 있는 Parameter들이 어떤 의미인지, 어떻게 바꿔야 자신의 목적에 부합되는지를 정리하면서, 사용하면 이 또한 충분할 것 같다는 생각이다.
[Reference]
Hao Dong, Zihan Ding, Shanghang Zhang Eds. "Deep Reinforcement Learning Fundamentals, Research and Applications", Springer, doi.org/10.1007/978-981-15-4095-0, 2020.
'최신 기술동향 > 인공지능 (AI)' 카테고리의 다른 글
OpenAI Gym을 이용한 Environment 설계 (0) 2020.08.30 Distributive Dynamic Spectrum Access with DRL 논문 리뷰 (1) 2020.08.17 Deep Reinforcement Learning for Multi-Agent systems 논문 리뷰 (1) 2020.08.06 RNN vs LSTM vs GRU (0) 2020.08.01 딥러닝의 개념 (0) 2020.07.07