-
Attention & Transformer의 개념최신 기술동향/인공지능 (AI) 2020. 12. 13. 08:23반응형
이번 글에서는 시계열 분석에서 State-of-Art라고 할 수 있는, Transforemer에 대해 정리해보고자 한다. 일반적으로 시계열 분석이라 하면, Recurrent Neural Network (RNN)이나 Long-Short Term Memory (LSTM)알고리즘을 배운다. 그것보다 조금 더 최신이면서, 간단한 알고리즘으로 GRU가 소개되었다. RNN의 장기간 학습 과정으로 인해 소실되는 정보들 중에 필요한 부분 (Remember, forget)들을 뒤의 State로 넘겨주면서 장기간 학습이 가능해지게 되었다. 이처럼 기존 RNN의 약점을 보완하는 LSTM과 이를 잇는 GRU는 Motivation도 직관적으로 이해하기도 편하고, 사용하기도 편한다. Tensorflow나 Keras에서는 해당 Layer를 Import하고, Input의 Shape을 맞춰준 후에, Layer에 넣기만 하면 결과값을 뽑아준다. 하지만, 이를 능가하는 성능을 보이는 Transformer가 등장했다.
Seq2Seq와 Attention
Transformer를 이해하기 위해서는 Sequence-to-Sequence(Seq2Seq)와 Attention이라는 개념부터 정리할 필요가 있다. Sequence-to-Sequence는 이름을 통해 직관적으로 이해하기 쉽듯이, 어떤 Sequence (연속된 데이터)들을 다른 Sequence로 Mapping하는 알고리즘이다. 가장 알기 쉽게, 한글로 작성된 문장을 영어로 작성된 문장으로 번역하는 Translation이 가장 많이 언급되는 Application이라 할 수 있다. Seq2Seq은 크게 정보를 압축하는 Encoder 부분과 이를 통해 새로운 Data를 생성해내는 Decoder 부분으로 나눠져 있다. 번역으로 예를 들면, 압축되는 정보들은 '단어 및 어간'에 관한 정보들로 표현될 수 있을것이다. 많은 시계열 분석에 LSTM를 적용할 때, 잘 작동하는 경우가 많지만, LSTM의 Encoder에서 Decoder로 들어가는 과정에서, 전달되는 정보에서 소실되는 시간 정보들이 생기게 되었다. 예를 들어, output Sequence를 얻기 위해서는 단어의 Mapping만으로 충분한 것이 아니라, Keyword와 중요한 부분들에 대한 정보가 필요하다.
이를 위해서 나온 개념이 Attention이다. 쉽게 설명하면, 'Input Data의 이 부분 (Time Step)이 중요해요! 집중해주세요!'라고 하는 수치들을 같이 output으로 넘겨주는 방식이다. 따라서, output sequence를 생성해내는 매 Time step마다 이전 input time step들을 다시 보고 중요하다는 부분을 참고해서 output을 생성하는 방식이다. 말만으로는 매우 직관적이고 좋은 방법이지만, 구현으로 들어가면 어떻게 '이 부분이 중요해요'라는 수치를 만들지를 알아야 한다. 다양한 방식들이 있지만, 가장 이해하기 쉽고 자주 언급되는 닷 프로덕트 어텐션으로 정리해보자.
Dot product Attention을 위해서는 Encoder의 Hidden state (h)와 Decoder의 Hidden state함수 (s)가 얼마나 유사한지를 표현하기 위한 내적으로 시작한다. 이 글만이 아니더라도, 두 분포의 유사도를 비교할 때 내적을 많이 사용한다는 점을 알고 있으면 좋다. Dot product Attention에는 내적이 사용되지만, 다른 Attention 함수들도 있으니, 찾아보고 여러 함수를 test해보는 것도 좋을 것 같다. (e.g., scaled dot, concat) 이렇게 내적으로 얻은 Attention score들을 Softmax 함수에 넣어서 Attention Distrubtion을 얻을 수 있다. 구한 Attention Distribution 값과 Encoder의 Hidden state와 가중합을 해서, Attention Value값을 구하여 Decoder의 Hidden state 차원 밑에 그대로 붙이고 (Concatenate), 이를 output 계산의 input으로 넣으면 Attention 알고리즘이 마무리 된다. 여기서의 포인트는 'Input들이 얼마나 output 생성에 기여하는지를 표현하는 Attention 알고리즘의 개념'이다. 이를 이용해서 Transformer가 구성되어 있기 때문에, 개념적으로는 어느 정도 알고 있어야 한다.
Transformer
A. Encoder
이제 본격적으로 Transformer를 정리해보자. RNN, LSTM의 약점으로 많이 언급되었던 것은, 단어를 순차적으로 입력받아서, 이를 계산하기 때문에, 병렬처리가 어렵다는 점이었다. 하지만 이 순차적으로 입력받는 것이, 각 input의 위치정보를 반영할 수 있게 해주었다. Transformer는 순차적으로 Data를 넣는 것이 아니라, Sequence를 한번에 넣음으로써 병렬처리가 가능하면서도, Attention 등의 구조를 통해 어떤 부분이 중요한지를 전달하여, 위치정보를 반영할 수 있게 되었다. Transformer의 전체적인 구조는 다음과 같다.

Transformer Architecture 이 그림은 Transformer 논문에서 가져온 논문이다. 하나씩 보면, 먼저 Embedding이라는 단계가 있다. Embedding은 다른 알고리즘에서도 많이 쓰는 방식으로, data를 임의의 N-dimension data로 만들어주는 단계다. 자연어 처리에서는 단어 등의 단위를 표현하는 N-dimension 데이터로 만들어주는 단계다. 본격적인 Transformer는 Positional Encoding으로 시작한다. 앞에서 설명했듯이, RNN이나 LSTM처럼 순차적으로 데이터를 넣어주지 않기 때문에, 데이터의 위치정보를 전달해주는 방법이 필요한데, Positional Encoding이 이 역할을 담당한다. Positional Encoding은 'Sequence 내에서 해당 정보의 위치 정보'와 'Embedding된 데이터'를 사인함수와 코사인함수 형태로 만들어서 다음 Layer의 Input으로 전달하게 된다. 쉽게 설명하면, Embedding을 할때 위치 정보까지 함께 넣어주자라는 내용이다. 이런 방식으로, Transformer는 해당 Input의 위치를 반영한 pre-processing을 할 수 있게 된다.
이렇게 정리된 Input Data들은 본격적으로 Encoder로 들어간다. Encoder는 Multi-head Self Attention / Add & Normalize / Position-wise FFNN라는 모듈들로 구성되어 있다. Multi-head Self Attention은 앞에서 정리한 Attention과 비교했을 때 살짝 차이가 있다. Attention이 Encoder의 Hidden state와 Decoder의 Hidden state를 연산해서 Attention score값들을 계산했다면, Self-Attention은 Encoder로 들어간 벡터와 Encoder로 들어간 모든 벡터를 연산해서 Attention score 값을 구한다. 이 부분이 매우 헷갈렸지만, 이런 Self-Attention을 통해서 각 Input Data들의 유사도를 추정할 수 있다. 만약 'The Animal didn't cross the street, because it was so tired'라는 문장에서 it이 Animal을 가리키는건지 street를 가리키는 것인지 알기 위해, 우리가 독해를 하면서 it이 무엇에서 오는건지 학습하는 것과 비슷한 방식을 거칠 수 있다. 이를 위해 Attention 함수의 Query (Q), Key (K), Value (V)를 의미하는 Weight 행렬과 'scaled Dot-Product Attention'방식으로 연산하여 Attention Value Matrix (a)를 만들어낸다. 이 과정에서 d_model개의 차원을 num_heads로 나눠지는 갯수만큼의 그룹으로 묶어서 d_model/num_head 개의 Attention value matrix를 뽑아낸다. 직관적으로는 여러 head를 가지는 Attention value matrix를 뽑아냄으로써 다양한 관점으로 연산을 할 수 있게 만드는 것이다. 이렇게 여러개로 나온 Attention value matrix는 다시 d_model 차원으로 합쳐진다.
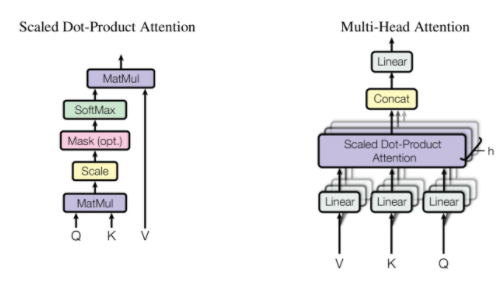
Multi-head Self Attention Add & Normalization은 Residual Connection과 layer Nomralization이다. Residual Connection은 CNN을 공부할 때 RseNet을 공부한 사람들은 어렵지 않게 알 수 있다. 연산을 한 부분과 안 하는 부분이 합쳐지도록 만든 것이다. 이렇게 함으로써, 층이 쌓일 때, 뒤쪽까지 학습이 잘 전달되지 않는 것을 방지할 수 있다. Layer Normalization은 정규화에 많이 소개되는 부분이기 때문에 가볍게 넘어간다. 그 다음으로 들어가는 FFNN은 쉽게 얘기하면 Fully connected layer로 어려운 점 없이 넘어갈 수 있다. 이렇게 Multi-head Self Attention / Add & Normalize / Position-wise FFNN라는 모듈들로 구성된 Encoder 함수를 N층 쌓고 여기서 나온 데이터들이 Decoder로 흘러간다.
B. Decoder
Decoder로 Encoder처럼 Positional Encoding과 Multi-head Self Attention을 한다는 점은 비슷하지만, 크게 두가지의 차이가 있다. Multi-head Self Attention에 Masked가 들어갔다는 점이 첫 번째 차이점인데, Decoder는 현재까지 들어온 데이터 보다 미래의 데이터를 보면서 학습하면 안 되기 때문에, 미래에 해당하는 Attention score들에는 매우 작은 음수값 (-1e9)을 넣어서 이 부분을 Masking해버린다. 그리고 한번 더, Attention을 진행하는데, 이 때는 Self-Attention이 아니라, 앞에서 배웠던 일반적인 Attention을 사용하여 Output을 추측하는데 사용한다. 이 때의 Input으로는 Decoder에서 사용한 Masked Attention Matrix와 Encoder에서 만든 Matrix를 Attention에 넣게된다. 중간에 연결되는 FFNN과 Add & Normalization Layer는 앞에서 설명했기 때문에 스킵한다. 이렇게 완성된 Decoder를 M층 쌓고 마지막으로 몹시 반가운 Dense Layer와 Softmax Layer로 넣으면 Transformer가 완성된다.
수학적인 부분과 직관적으로는 어려운 부분이 없지만, 중간중간에 Layer를 쪼개고, 연산해서 합치는 부분이 익숙해져야겠다는 생각을 했다. 다행히, Keras의 Functional API나 Tensorflow이 이렇게 연산하는 부분들을 구현하기 쉽게 설계되었기 때문에 Transformer Github의 코드를 하나씩 따라가면 어렵지 않게 이를 구현할 수 있다. 전처리를 하고, layer를 구성하는 과정에서 데이터들의 dimension을 맞춰주는 것이 생각보다 까다롭다는 생각을 했다.
Conclusion
성능 측면에서도 기존 RNN, LSTM보다 좋고, 병렬처리가 가능한 Transformer가 상당히 매력적으로 다가왔다. 하지만, 딱봐도 모델이 상당히 무거워지는 것 같아서, 정말 필요할 때만 사용해야겠다는 생각을 했다. 시계열 분석이라고 하면, 전통적인 방식에 속하는 ARIMA 같은 Machine Learning 알고리즘, Deep Learning을 사용하는 RNN, LSTM 등으로 사용할 수 있는 알고리즘이 거의 정해져있었다. 하지만, Transformer같은 Attention을 이용한 다양한 알고리즘들이 추가적으로 나올 것으로 보인다. 하지만, 조금 무거워 보이는 Transformer를 조금 경량화하는 버전이 나오면 좋겠다는 생각을 했다. 이렇게 정리한 Transformer 알고리즘으로, 쉽게는 주식시장 (Stock Market)에 사용할 수도 있고, 번역 등 자연어 처리에 사용할 수 있겠다는 생각을 했다. 하지만, ms 단위로 의사결정을 해야하는 통신 시스템에서 사용하거나 스마트폰에 넣기에는 GPU 등의 고성능 스펙을 사용해야할 것 같아서, 조금 경량화 버전이 필요하지 않을까라는 생각을 해본다.
Reference
[1] A. Vaswani, N. Shazeer, N. Parmar, and J. Uszkoreit, “Attention is all you need,” arXiv preprint arXiv:1706.03762, 2017.
반응형'최신 기술동향 > 인공지능 (AI)' 카테고리의 다른 글
AI 알고리즘 경량화 (0) 2021.05.01 Hyper-Parameter Tuning 및 AutoML 논문 리뷰 (2) 2021.02.06 Deep Q Network (DQN) (1) 2020.10.04 Federated Learning (연합학습) (0) 2020.09.20 OpenAI Gym을 이용한 Environment 설계 (0) 2020.08.30